Still in progress…
这篇论文希望通过learning的方式得到参数更新的方法。
在RL领域中 ,有很多不同的更新方式来优化value function 或者 policy。 这篇论文希望可以直接优化求解出更新的方式,(或者目标)。
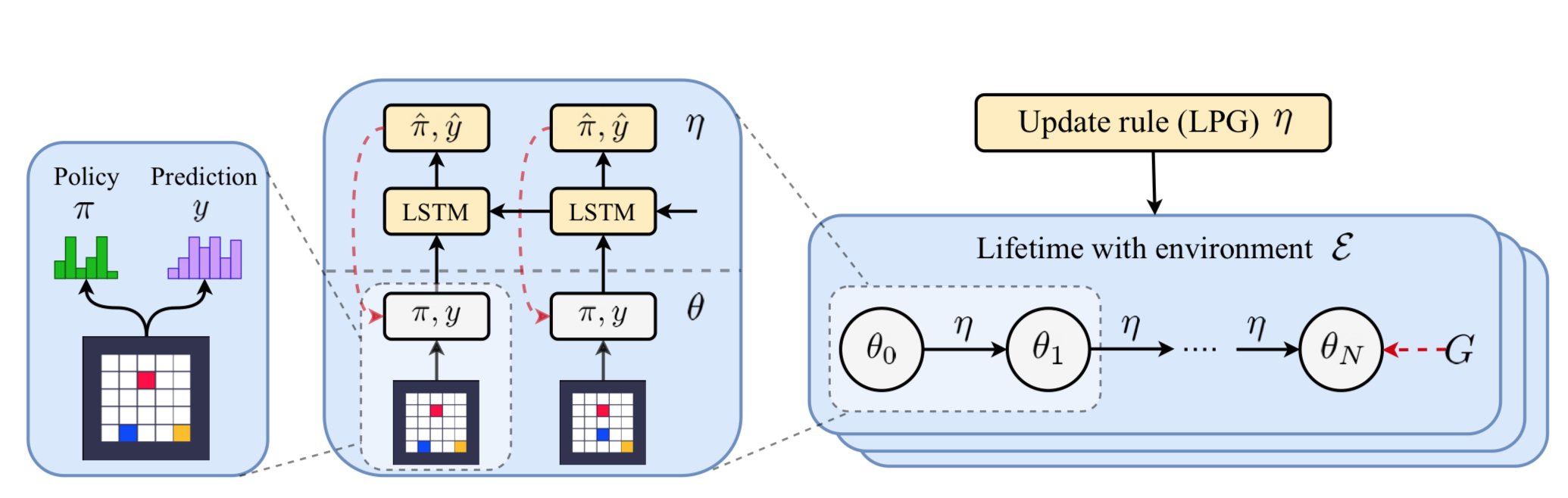
本文的核心在于通过学习一个trainer来指导predictor的预测。 这里的trainer 是一个时序的处理模块,其每一个时刻会输出policy \(\hat{\pi}\) 以及 \(\hat{y}\).
这个由trainer 生成的\(\hat{\mathcal{\pi}}\) 和\(\hat{\mathcal{y}}\) 就是作为另一个模型输出\(\mathcal{\pi}, \mathcal{y}\)的监督信号。
模型的参数是由 \(\theta\) 所确定的,可以通过更新 \(\theta\)来使得 \(\pi \rightarrow \hat{\mathcal{\pi}}\), \(y \rightarrow \hat{\mathcal{y}}\).