Pose estimation with Deep Convolutional Neural Network
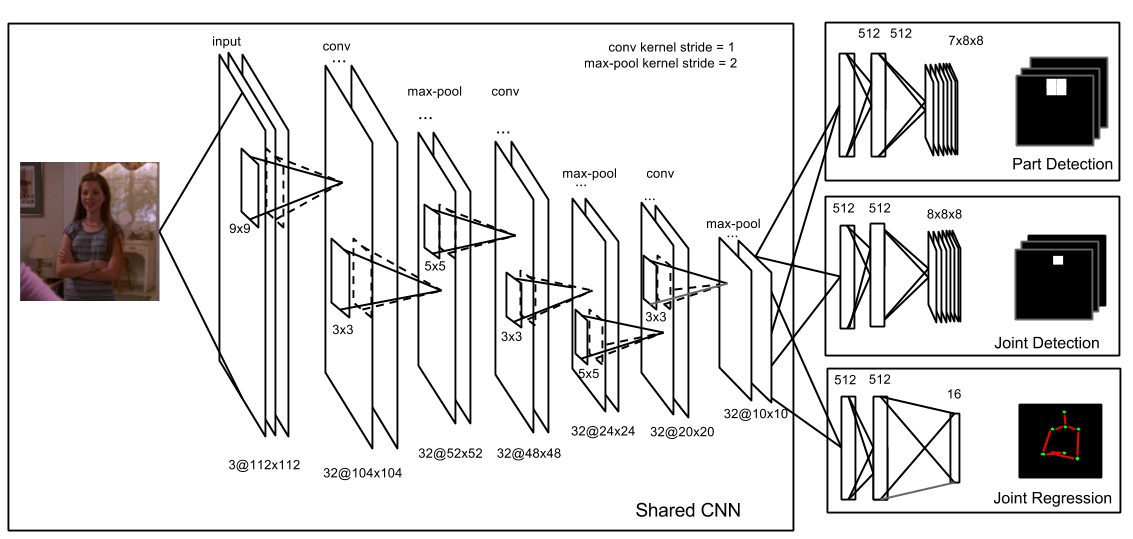
Human pose estimation is a popular research topic in computer vision with wide potential in many applications. In general, the pose estimation approaches can be divided into two categories: 1) regression based methods, the goal of which is to learn the mapping from input feature space to the target space (2d/3d coordinates of joint points); 2) optimization based methods. As for the first type of approach, the input features are expected to have pose information preserved. One of the most successful methods in the second category is Pictorial Structural Model (PSM) which takes into account both detection scores for each body part and pairwise spatial relationships between parts. For both approaches, the quality of features are critical to the performance. We propose a heterogeneous multi-task learning framework for 2d human pose estimation from monocular images using a deep convolutional neural network which combines regression and part detection into a united model. In particular, we simultaneously learn a human pose regressor and sliding-window body-part and joint-point detectors in a deep network architecture. We show that including the detection tasks helps to regularize the network, directing it to converge to a good solution. We report competitive and state-of-art results on several datasets. We also empirically show that the learned neurons in the middle layer of our network are tuned to localized body parts.


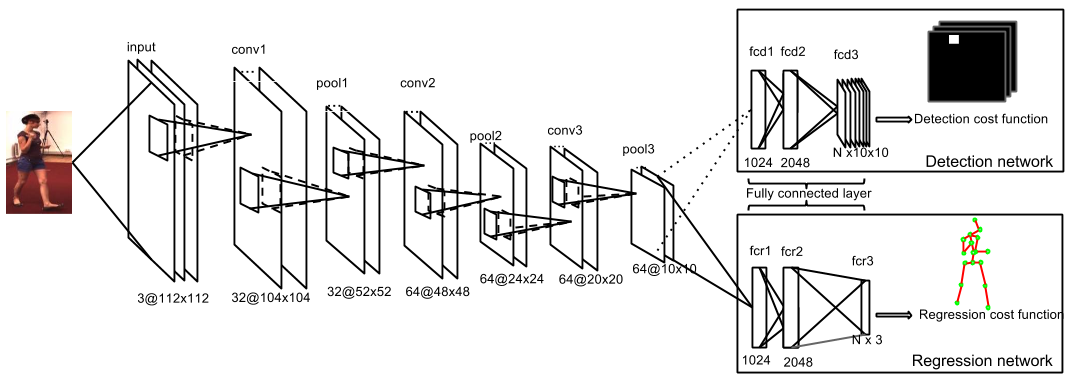
In general, recovering 3D pose from 2D RGB images is considered more difficult than 2D pose estimation, due to the larger 3D pose space, more ambiguities, and the ill-posed problem due to the irreversible perspective projection. Although using depth maps has been shown to be effective for 3D human pose estimation, the majority of the media on the Internet is still in 2D RGB format. We extend our multi-task framework for 3D human pose estimation from monocular images. We train the network using two strategies: 1) a multi-task framework that jointly trains pose regression and body part detectors; 2) a pre-training strategy where the pose regressor is initialized using a network trained for body part detection. We compare our network on a large data set and achieve significant improvement over baseline methods.
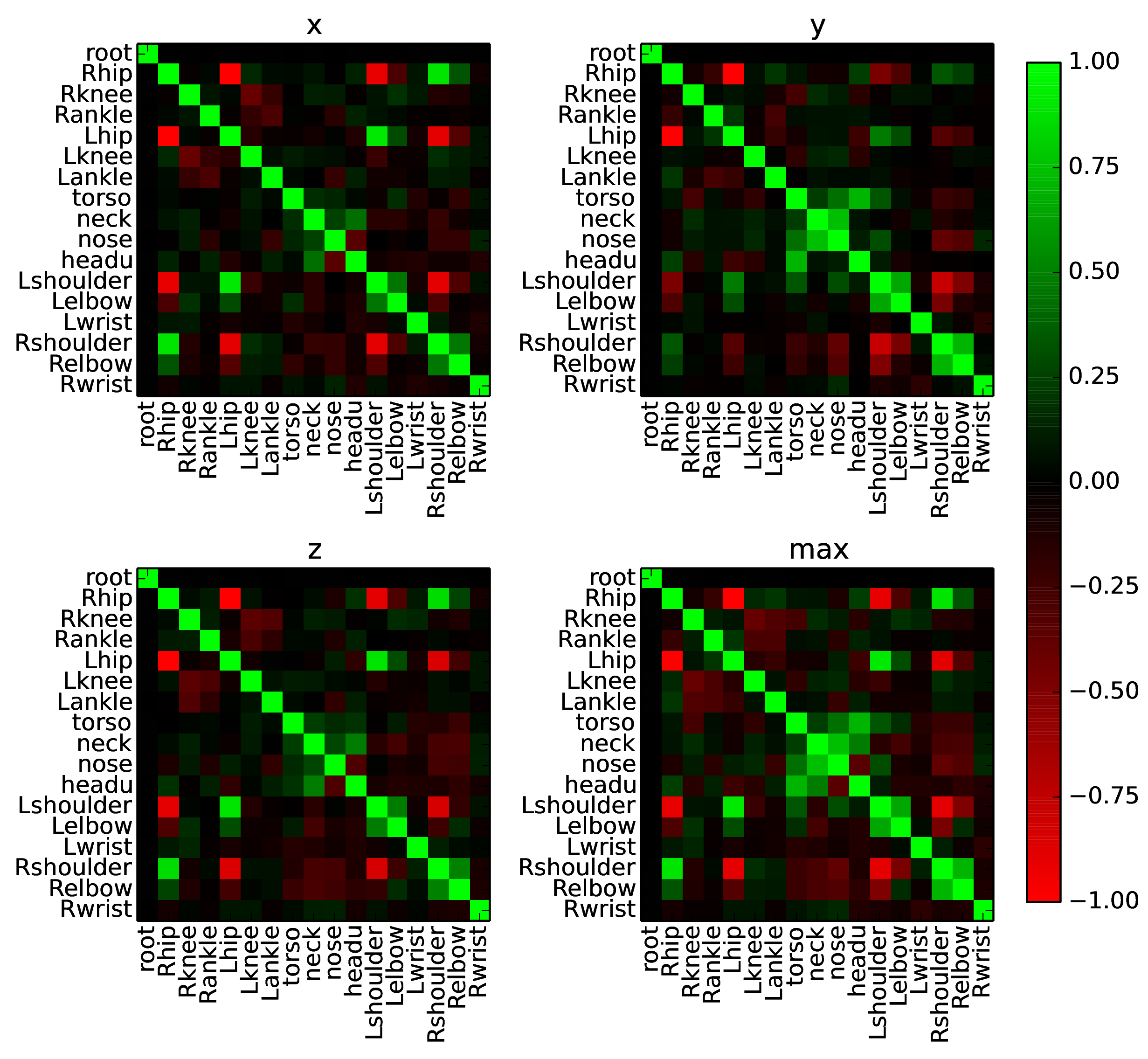
Human pose estimation is a structured prediction problem, i.e., the locations of each body part are highly correlated. Although we do not add constraints about the correlations between body parts to the network, we empirically show that the network has disentangled the dependencies among different body parts, and learned their correlations.